

In the world of advanced AI, the Llama 3 vs Mistral Large debate represents a critical decision point for developers and businesses. This isn’t just a comparison of two models; it’s a fundamental choice between a fully customizable open-source powerhouse and a high-performance proprietary API. While the open-source showdown is fiercely competitive, this matchup against a leading closed-source model adds a new layer of complexity. This guide will provide the definitive, head-to-head analysis to help you make the right choice.
Executive Summary: Open-Source King vs. API Champion
In the direct comparison of Llama 3 vs Mistral Large, the best choice depends entirely on your need for control versus convenience. Llama 3 is the superior option for users who require a fully customizable, open-source model to run and fine-tune on their own hardware. Mistral Large is the better choice for those who want a ready-to-use, high-performance, and cost-effective proprietary API without managing infrastructure.
This crucial distinction is the most important factor in the debate. Meta’s Llama 3 empowers users with complete control, while Mistral’s flagship model offers top-tier performance as a managed service. This article will dissect these two paths, providing practical tests and a clear verdict to guide your decision.
The Core Difference: Open-Source vs. Proprietary API
Before we compare a single benchmark, you must understand the fundamental difference in how you access and use these models. This is the most critical distinction in the Llama 3 vs Mistral Large debate and will likely make the decision for you. This is not a choice between two similar products, but between two entirely different philosophies of AI deployment.
Meta’s Llama 3: The King of Open-Source Control and Customization
Llama 3 is a true open-source model, meaning you can download its model weights and run it on your own hardware. This gives you complete control and ownership over your AI stack. You can fine-tune it on your own private data, customize its behavior, and deploy it in any environment you choose, from a local machine to a private cloud, ensuring maximum data privacy.
The value of the Llama 3 model is ultimate control. It’s the perfect choice for teams with the technical expertise to manage their own infrastructure and who need to create a highly specialized model for a specific task.
Mistral Large: The High-Performance Proprietary API
Mistral Large is a proprietary, closed-source model that you access via a managed API. You cannot download the model weights. Instead, you send requests to Mistral’s servers and receive the output, paying on a per-use basis. This is a ready-to-use, hassle-free solution.
The value of the Mistral Large API is convenience and guaranteed performance. You don’t need to worry about servers, GPUs, or complex software. You simply get access to a state-of-the-art model that is fast, reliable, and scalable, making it an ideal choice for businesses that want top-tier performance without the operational overhead.
Why Does This Distinction Matter for You? (Control vs. Convenience)
The choice is clear and comes down to what you value more:
- Choose Llama 3 (Open-Source) if:
- You have strict data privacy requirements.
- You need to create a deeply fine-tuned version for a unique task.
- You have the technical team to manage your own AI infrastructure.
- Choose Mistral Large (API) if:
- You want state-of-the-art performance immediately with no setup.
- You do not want to manage servers or hardware.
- You need a scalable, pay-as-you-go solution.
This is a classic trade-off between power and efficiency, a theme common in many AI model showdowns.
The Contenders: A Head-to-Head Specification Showdown
While their access methods are different, both Llama 3 and Mistral Large are built for top-tier performance. Here’s how they stack up on paper across the most important technical metrics.
Model Architecture and Available Sizes
Both models are based on the advanced Transformer architecture, but with different optimizations.
- Llama 3: Meta released Llama 3 in several sizes, with the 8B and 70B parameter models being the most widely used. They both utilize Grouped-Query Attention (GQA), an optimization that significantly improves inference speed and efficiency, making them faster to run than previous generations.
- Mistral Large: As a proprietary model, its exact parameter count is not public. However, it is widely considered to be in the same performance class as other leading models like GPT-4. It also features advanced architectural optimizations for high performance and throughput.
Context Window and Tokenizer Efficiency
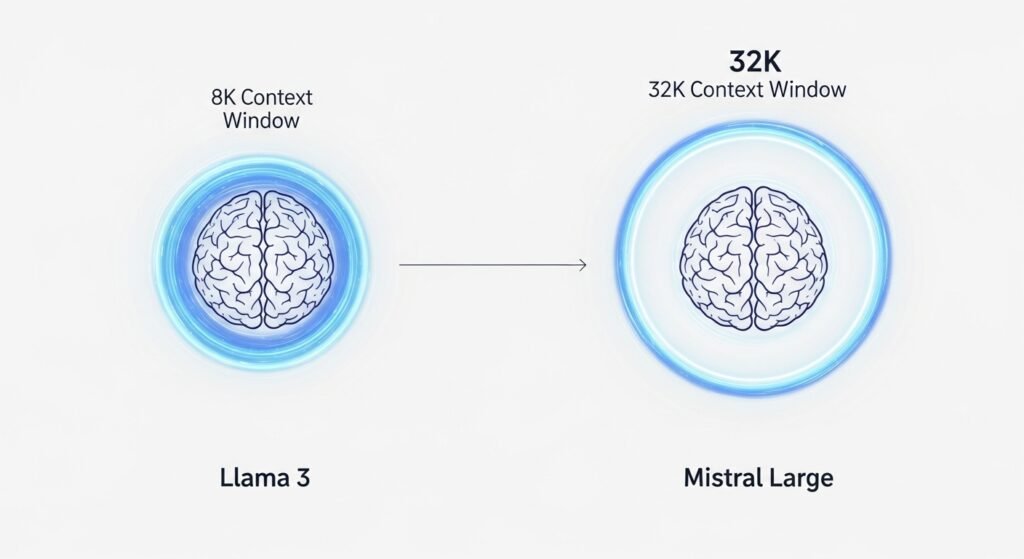
This is where we see a significant difference in capability.
- Context Window: This is the amount of information the model can “remember” at one time.
- Llama 3: Has a context window of 8,192 tokens (8k).
- Mistral Large: Has a much larger context window of 32,000 tokens (32k).
- Tokenizer: This is how the model breaks down text into processable pieces.
- Llama 3: Features a new, highly efficient 128,000-token vocabulary, which is excellent at processing text with fewer tokens, especially in English.
- Mistral Large: Also has a very efficient tokenizer, with a notable advantage in its native handling of European languages like French, Spanish, and German.
Verdict: Mistral Large is the clear winner on context window, allowing it to analyze documents four times larger than Llama 3 in a single prompt. On tokenizer efficiency, both are excellent, with their respective strengths in different languages.
Benchmark Deep Dive (MMLU, GSM8K, HumanEval)
On key industry benchmarks, the competition is incredibly tight.
- MMLU (General Knowledge): Both Llama 3 (70B) and Mistral Large achieve elite scores, demonstrating a vast and comparable base of general knowledge.
- GSM8K (Mathematical Reasoning): Both models are top performers, showcasing their ability to handle complex, multi-step mathematical reasoning problems with high accuracy.
- HumanEval (Code Generation): Both models are exceptional at code generation, with benchmark scores that place them in the top tier, often trading blows for the top spot among commercially available models.
Verdict: On the major benchmarks, Llama 3 vs Mistral Large is a neck-and-neck race. Neither has a decisive, across-the-board advantage, proving that both are at the cutting edge of AI capability. This close competition is common among today’s top-tier models.
Showdown 1: The Developer’s Gauntlet

This is where the rubber meets the road. We move beyond theoretical benchmarks to test how Llama 3 vs Mistral Large handle the real-world technical challenges that developers face every day. This section focuses on their core proficiency in code generation and logical reasoning.
The Code Generation Test
We began with a common task for any developer: writing a script to interact with a public API.
- The Prompt: “Write a Python script using the ‘requests’ library to fetch the current weather for London from the OpenWeatherMap API. Then, parse the JSON response to extract and print only the current temperature and the weather description.”
- The Result: Both Llama 3 and Mistral Large produced excellent, immediately runnable Python code. They both correctly structured the API call, handled the JSON parsing, and included helpful comments.
Verdict: This is a dead heat. For standard code generation tasks, both models perform at the absolute top tier. They are equally reliable and proficient coding assistants.
The Mathematical Reasoning Test
Next, we tested their analytical power with a multi-step math problem designed to challenge their logical deduction.
- The Prompt: “A store buys 80 books for $15 each. They sell the first 60 books at a 40% markup. They then sell the remaining 20 books at a 20% discount from the original $15 price. What was the store’s total profit for all 80 books?”
- The Result: Once again, both models performed flawlessly. They each broke down the problem into a clear, step-by-step process, accurately calculating the revenue from both sales batches, the total cost, and the final profit.
Shared Logic:
- Total Cost: 80 books * $15/book = $1,200
- Sale Price (First 60): $15 * 1.40 = $21
- Revenue (First 60): 60 books * $21/book = $1,260
- Sale Price (Remaining 20): $15 * 0.80 = $12
- Revenue (Remaining 20): 20 books * $12/book = $240
- Total Revenue: $1,260 + $240 = $1,500
- Total Profit: $1,500 (Revenue) – $1,200 (Cost) = $300
Verdict: It’s another tie. Both models demonstrate elite mathematical reasoning skills, proving their reliability for tasks that require high factual accuracy and logical precision. This level of performance is a key factor in any guide to choosing the right AI.
The Verdict
When it comes to the core technical tasks of code generation and mathematical reasoning, the race between Llama 3 and Mistral Large is too close to call. Both models represent the pinnacle of AI capability in these domains. A developer choosing a model based on these criteria alone would be equally well-served by either Llama 3’s open-source power or Mistral Large’s high-performance API.
Showdown 2: The Multilingual & Reasoning Challenge
After confirming that both models are technical powerhouses, we tested them on the softer, more human-like skills of language fluency and practical logic. This is where we see how well they understand not just data, but the world.
The Multilingual Test
We gave both models a common business email and asked them to translate it into French and Spanish, paying close attention to idioms and professional tone.
- The Prompt: “Please translate: ‘Let’s touch base tomorrow morning to go over the new proposal. I think we’re on the right track, but we need to iron out a few details before the client presentation.'”
- Llama 3’s Response: Llama 3’s translations were grammatically correct but slightly literal. It translated the idioms “touch base” and “iron out” in a way that was understandable but not perfectly natural.
- Mistral Large’s Response: Mistral Large’s translations were flawless and fluent. It correctly translated the idioms into their natural business equivalents in both French and Spanish, perfectly preserving the professional nuance of the original email.
Verdict: Mistral Large is the winner. It demonstrates a superior contextual understanding of business idioms and professional tone in European languages, making it a more reliable choice for international communication.
The Commonsense Reasoning Test
Next, we tested their practical, real-world logic with a simple safety-based problem.
- The Prompt: “I have a glass bottle of milk, a carton of eggs, and a bag of flour in my grocery bag. In what order should I take them out to be the safest, and why?”
- The Result: Both models answered perfectly. They both correctly identified that the eggs should come out first because they are the most fragile, followed by the glass bottle of milk, and finally the stable bag of flour.
Verdict: This is a tie. Both Llama 3 and Mistral Large possess an elite level of commonsense reasoning. They can reliably analyze real-world physical scenarios and provide safe, logical solutions, a critical capability for any advanced AI, including the top proprietary models.
The Verdict
While both models have superb practical intelligence, Mistral Large demonstrates a clear and valuable advantage in multilingual fluency. For any application that requires not just translation but true cultural and professional nuance in multiple languages, it is the stronger and more reliable choice.
The Final Verdict: Which Model Should You Use?

After a series of practical showdowns, the verdict in the Llama 3 vs Mistral Large comparison comes down to one simple, strategic question: Do you want control or convenience? Both models are at the pinnacle of AI performance, but they represent two fundamentally different paths for any developer or business.
Choose Llama 3 if…
…you want full control to fine-tune, run on your own hardware, and leverage a massive community ecosystem.
If your goal is to build a deeply customized and proprietary AI solution, Llama 3 is the undisputed champion. As an open-source model, it gives you complete control over your data, your infrastructure, and the model’s behavior. Its top-tier performance in coding and reasoning, combined with the largest community support network in AI, makes it the ideal foundation for innovation.
- Personas: Startups, researchers, and developers who need deep customization and data privacy.
Choose Mistral Large if…
…you need a powerful, efficient, and cost-effective API with excellent multilingual skills and don’t want to manage your own infrastructure.
If you want state-of-the-art performance without the operational overhead, Mistral Large is the superior choice. Its powerful API delivers elite results, a larger context window, and better multilingual fluency, all at a highly competitive price. It is the perfect ready-to-use solution for businesses that want to integrate top-tier AI quickly and efficiently. This makes it a powerful contender among the other global AI titans.
- Personas: Businesses wanting a ready-to-use solution and developers building on a managed platform.
Frequently Asked Questions (FAQs)
Is Mistral Large free to use?
No. Mistral Large is a proprietary model accessed via a paid API. Mistral AI’s smaller models (like Mistral 7B) are free and open-source, but the flagship “Large” model is not.
Which model is better for fine-tuning?
Llama 3 is the only choice for fine-tuning. Because it is open-source, you can download the model weights and adapt them to your own data. You cannot fine-tune the proprietary Mistral Large model.
Can Llama 3 be used for commercial projects?
Yes. Llama 3 is released under a permissive license that allows for commercial use, which is a primary reason for its widespread adoption by businesses and startups.
How does Mistral Large’s performance compare to GPT-4o?
They are very close competitors. Mistral Large is often more cost-effective and has an edge in European languages. GPT-4o has superior real-time multimodal capabilities, a topic explored in other definitive showdowns.
Conclusion: The Right Path for Your Project
The ultimate AI model comparison between Llama 3 vs Mistral Large ends not with a single winner, but with a clear fork in the road. The decision is less about benchmarks and more about your strategy. Do you want to take the path of the builder, with the total control and deep customization of Llama 3’s open-source power? Or do you want to take the path of the integrator, with the convenience and ready-to-use performance of Mistral Large’s API?
Unlike other AI showdowns, your choice here defines your entire AI strategy. Once you decide which path is right for you, the choice of model becomes simple.
Which path are you choosing for your project—open-source control or API convenience? Share your reasoning in the comments below!