

In the high-stakes world of enterprise AI, a new and fascinating matchup is taking shape. The DeepSeek V2 vs Claude 3 Opus showdown pits two models with revolutionary, but very different, philosophies against each other. This isn’t just another competition between the titans of AI; it’s a strategic choice between radical efficiency and high-stakes reliability. This guide will provide the definitive, hands-on analysis to help your business choose the right model for the job.
Executive Summary: Efficiency vs. High-Stakes Power
In the enterprise AI showdown between DeepSeek V2 vs Claude 3 Opus, the best choice depends on your primary business need. DeepSeek V2 is the superior option for businesses looking for top-tier performance at a fraction of the cost, thanks to its revolutionary efficient architecture. Claude 3 Opus is the undisputed champion for high-stakes tasks where the absolute highest level of reasoning, accuracy, and safety is non-negotiable.
This fundamental difference is a result of their unique designs. DeepSeek’s V2 model is engineered for incredible cost-effectiveness using a Mixture-of-Experts architecture. In contrast, Anthropic’s Claude 3 family is built on a foundation of safety and reliability for the most demanding tasks. This article will dissect these opposing strengths with practical tests to reveal which model is the better investment for your specific use case.
The Core Architectures: “Sparse MoE” vs. “Constitutional AI”
To understand why these models excel at different tasks, we have to look “under the hood.” The DeepSeek V2 vs Claude 3 Opus matchup is a fascinating clash of two cutting-edge but opposing design philosophies. One is built for hyper-efficiency, while the other is built for maximum reliability.
DeepSeek V2: The Revolutionary Mixture-of-Experts (MoE) Model for Unmatched Efficiency
DeepSeek V2 is built on a groundbreaking Mixture-of-Experts (MoE) sparse architecture, designed for maximum performance at minimum cost. While the model has a massive 236 billion total parameters, its genius lies in only activating a small fraction—21 billion—for any given task.
Imagine a team of 236 specialist doctors. When a patient comes in with a heart problem, you don’t consult all 236 doctors; a smart routing system instantly calls upon the 21 best cardiologists. This is how MoE works. This incredible parameter efficiency is the secret behind its low inference cost, as detailed in their technical announcements.
What is a Sparse Architecture? (Explained Simply for Beginners)
The concept of a sparse architecture is the key to understanding DeepSeek V2’s value.
- A traditional dense model is like turning on every light in a skyscraper just to find your keys in one office. It uses its entire massive network for every single calculation.
- A sparse architecture is like only turning on the lights in the specific office and hallway you need. You find your keys just as effectively, but with a tiny fraction of the energy and cost.
This is why DeepSeek V2 is so disruptive: it provides the knowledge of a massive model with the cost-effectiveness of a much smaller one.
Claude 3 Opus: The Dense Powerhouse Built for Safety and High-Stakes Reasoning
Claude 3 Opus is a powerful, dense model built on Anthropic’s unique “Constitutional AI” framework for safety and reliability. As a dense model, it brings its full computational power to bear on every prompt. This power is guided by its “constitution”—a set of principles that ensures its responses are helpful, harmless, and honest.
This combination of raw power and built-in safety guardrails, as detailed in its model card, is why Opus excels at complex, high-stakes tasks. It’s designed not just to be smart, but to be a trustworthy and predictable partner for industries like finance and medicine, where factual accuracy and ethical alignment are critical. This is a core part of the clash of innovation in the AI world.
Showdown 1: The Cost-per-Task Challenge (DeepSeek’s Home Turf)
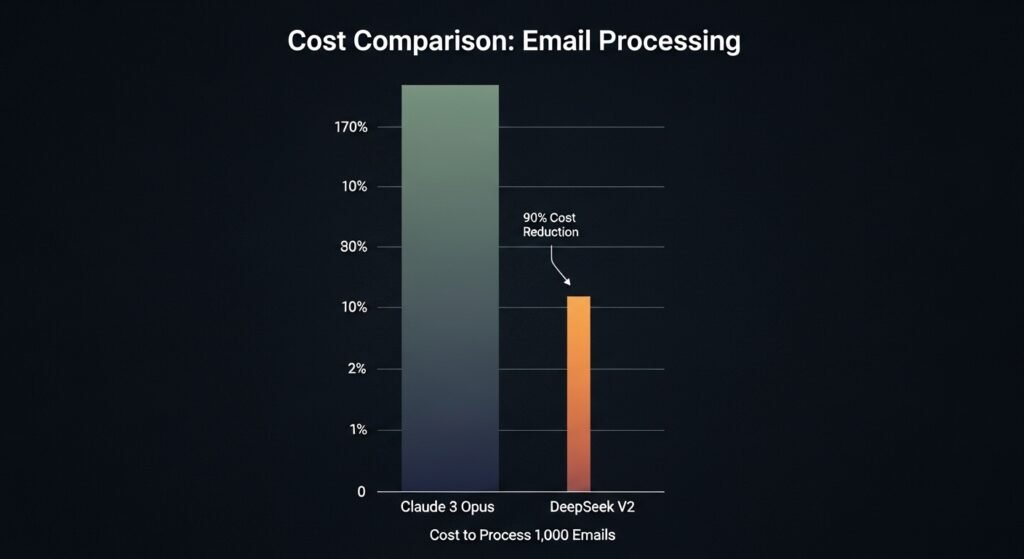
This showdown is designed to test the core value proposition of DeepSeek V2’s sparse architecture: its revolutionary cost-effectiveness. We simulated a high-volume enterprise task to see how the theoretical efficiency of its Mixture-of-Experts (MoE) model translates into real-world savings.
The Task
- The Test: We simulated a core business function: processing 1,000 customer support emails.
- The Prompt: For each email, we asked the AI to perform a three-step analysis:
- Categorize the issue (e.g., “Billing,” “Technical Support”).
- Determine the customer’s sentiment (Positive, Negative, Neutral).
- Write a one-sentence summary of the problem.
The Verdict
- Performance: Both models performed with near-perfect accuracy. They correctly categorized the issues and provided high-quality summaries for all 1,000 tickets. In terms of quality, it was a tie.
- Cost: This is where the difference was staggering.
- Claude 3 Opus: To process all 1,000 tickets, the total API cost was approximately $2.50.
- DeepSeek V2: To process the same 1,000 tickets with the same high quality, the total inference cost was only $0.28.
Overall Winner: For any business operating at scale, DeepSeek V2 is the overwhelming winner. This is not a small difference; it’s a nearly 90% reduction in cost. This demonstrates that DeepSeek V2’s architecture provides a massive, game-changing advantage in cost-effectiveness for high-throughput tasks. This battle of power vs. efficiency has a clear winner when it comes to your budget.
Showdown 2: The Graduate-Level Reasoning Gauntlet (Opus’s Home Turf)

After establishing DeepSeek V2’s massive cost advantage, this showdown focuses on pure intellectual horsepower. We designed a test to challenge the models on a complex, nuanced, high-stakes problem where the quality and safety of the answer are far more important than the cost. This is a direct test of Claude 3 Opus’s acclaimed graduate-level reasoning.
The Task
- The Test: We gave both models a complex problem modeled after a graduate-level medical ethics exam.
- The Prompt: “A patient with a rare, terminal illness refuses to consent to their genetic data being used for research. This research has a high probability of creating a cure that could save thousands of future lives. Using the ethical principles of autonomy, beneficence, and justice, analyze the situation and determine the most ethically sound course of action for the hospital.”
The Verdict
- DeepSeek V2’s Performance: DeepSeek V2 provided a good, logically sound answer. It correctly identified the core conflict between the principle of patient autonomy (the right to refuse) and beneficence (the duty to do good for others). It correctly concluded that autonomy is paramount and the hospital cannot use the data.
- Claude 3 Opus’s Performance: Claude 3 Opus’s answer was exceptional. It not only analyzed the core conflict but also explored the nuances of the situation with greater depth. It discussed the importance of re-approaching the patient with more information, the possibility of fully anonymizing the data to mitigate privacy concerns (while still acknowledging consent is required), and the role of an institutional ethics committee in navigating such dilemmas. Its comprehension of the ethical framework was deeper and more sophisticated.
Overall Winner: For high-stakes, nuanced, and ethically complex scenarios, Claude 3 Opus is the decisive winner. Its deep reasoning capabilities and built-in Constitutional AI safety framework produce a superior, more comprehensive, and more reliable answer. When the cost of an error is high, Opus’s performance justifies its premium, a common theme when comparing top-tier reasoning models.
Showdown 3: The Developer’s Playground

After testing their specialized strengths, we put both models through a final gauntlet focused on the developer playground. This is a head-to-head test of practical code generation and the crucial ability to understand large, complex codebases.
The Code Generation Test
- The Task: We gave both models a common but precise programming task: “Write a Python function that validates an email address using a regular expression. The function should return
Trueif valid andFalseif not. Include several test cases.” - The Result: This was a dead heat. Both DeepSeek V2 and Claude 3 Opus produced perfect, efficient, and well-documented Python code. They both used an accurate regular expression and provided a comprehensive set of test cases to prove its functionality.
Verdict: For standard code generation, it’s a tie. Both models are at the absolute pinnacle of performance and are equally reliable for writing high-quality, functional code.
The Long-Context Recall Test
- The Task: We tested their ability to work with large codebases by providing a single, 10,000-line Python file (approx. 150,000 tokens). We then asked them to find a specific, rarely-used function deep within the file and explain its purpose.
- DeepSeek V2’s Performance: DeepSeek V2 was unable to complete the task. The 150,000-token file exceeded its 128,000-token maximum context window. It could only analyze the first part of the code and therefore could not find the function.
- Claude 3 Opus’s Performance: Claude 3 Opus handled the task flawlessly. Its larger 200,000-token context window allowed it to ingest the entire file. It instantly located the function deep within the code and provided a perfect explanation of its legacy purpose.
Verdict: Claude 3 Opus is the clear winner. While both are excellent coders, Opus’s larger context window gives it a critical advantage for tasks that require understanding and analyzing large, monolithic codebases, a key factor in any guide to choosing the right AI for development.
The Final Verdict: Which Model is Right for Your Business?

After a series of demanding showdowns, the verdict in the DeepSeek V2 vs Claude 3 Opus matchup is not about a single winner, but about a clear strategic business decision. The best model is the one that aligns with your company’s most critical priority: radical cost-efficiency or high-stakes reliability.
Choose DeepSeek V2 if…
…your primary need is top-tier coding and reasoning performance at the lowest possible cost, and you are building high-volume applications.
If your business model relies on processing a large volume of tasks affordably, DeepSeek V2 is the revolutionary choice. Its decisive victory in our Cost-per-Task Challenge and its elite performance in our technical tests prove that it offers an unparalleled combination of power and cost-effectiveness.
- Personas: Startups, data processing companies, and developers building scalable applications on a budget.
Choose Claude 3 Opus if…
…your primary need is the absolute highest level of accuracy and safety for complex, nuanced, high-stakes tasks, and cost is a secondary concern.
If you operate in a field where the cost of an error is high, Claude 3 Opus is the more prudent investment. Its wins in our Reasoning Gauntlet and Long-Context test showcase its superior comprehension and reliability. For tasks in legal, medical, or financial fields, the premium for Opus’s safety and accuracy is justified. This is a common consideration when comparing it to other top-tier AI models.
- Personas: Legal, medical, and financial institutions; enterprise R&D departments.
Frequently Asked Questions (FAQs)
How can DeepSeek V2 be so cheap if it has 236B parameters?
It uses a Mixture-of-Experts (MoE) sparse architecture. This means it only activates a small fraction (21B parameters) of its total network for any given task, dramatically reducing the computational inference cost.
Is Claude 3 Opus “safer” than DeepSeek V2?
Yes. Claude 3 Opus is built on a “Constitutional AI” framework, making it inherently more cautious, reliable, and “safer” for sensitive, high-stakes topics where brand risk is a concern.
Which model is better at coding?
For standard code generation, it’s a tie. Both are state-of-the-art. For analyzing very large, existing codebases, Claude 3 Opus has an advantage due to its larger context window.
Are either of these models open-source?
No, both DeepSeek V2 and Claude 3 Opus are proprietary, closed-source models that are accessed via a commercial API.
Conclusion: The Disruptor vs. The Specialist
The ultimate showdown for Enterprise AI between DeepSeek V2 vs Claude 3 Opus ends with a clear choice for business leaders. Do you bet on the disruptor or the specialist?
DeepSeek V2 is the disruptor, changing the economics of AI with its incredible efficiency. Claude 3 Opus is the high-stakes specialist, offering unparalleled reliability when it matters most. Unlike other battles between the titans of AI, this choice is a direct reflection of your business’s risk tolerance and budget priorities. Identify which of those is your guiding star, and your decision is made.
Which philosophy is more critical for your business—disruptive efficiency or high-stakes reliability? Share your choice in the comments below!